The importance of action chunking in imitation learning
Action chunking is an open-loop control where at every control time step, a policy outputs a chunk (sequence) of actions into the future given the current observation. Usually the action sequence will be fully or partially executed before the next control time step. This is in contrast to the typical closed-loop control, where the policy observes the current observation, outputs only one action, observes the next observation, and so on.

So for imitation learning on a real robot, we are usually given a teleoperated sequence of (observation, action) pairs. It seems straightforward and optimal to just learn a closed-loop policy $\pi: o_t \rightarrow a_t$. After all, closed-loop means that the policy will be responsive to any sudden change in the environment and take actions accordingly. However, it turns out that action chunking, though seemingly suboptimal, is very important in this context for real-word performance of the policy, due to at least four reasons we will talk about below.
Modeling non-Markovian behaviors while avoiding causal confusion
The first two benefits of action chunking were actually discussed in the ALOHA/ACT (action chunking transformer) paper [Zhao et al. 2023].
A human demonstrated trajectory can be non-Markovian if there is any pause in the middle of the trajectory. The pause ends after a while and the robot starts moving again. However, the policy will get the same observation $o_t$ to decide between staying stationary or moving. Thus it’s theoretically impossible for the proper action to be decided based on the current observation alone.
One way to avoid this non-Markovian property is to augment the observation with historical information, such as past actions. If the policy knows how many stationary actions have been taken in the past, it will probably know when to end the pause.
But this historical information will introduce one notorious challenge for imitation learning: causal confusion [Haan et al. 2019]. In some scenarios such as self-driving where the demonstration tends to contain a continuous segment of very similar actions-for example driving forward at a constant speed-the policy network will be lazy by learning an identity mapping from the previous action to the current action. That is, it will directly copy the previous action for the most of the time. The policy is unable to differentiate the correlation (actions are similar between time steps) from the cause (we really want to drive forward given the current camera data).
Neural network is nothing but a powerful correlation learner. Typically SGD will drive an NN to take the easiest path to minimize the loss function. When there is an easy correlation signal in the training data, the easiest path would be to learn this particular correlation. In the example below, if there is only one “brake” action in a long action window, this critical signal can be easily ignored by the policy network during loss optimization. As a result, the actual informative observations provide little signal for the output actions.

Generally, the more information is contained in the observation space, the more likely causal confusion will happen for imitation learning. Action chunking can mitigate the non-Markovian issue but without introducing additional input signals. Based on the current observation alone, action chunking policy predicts a sequence of actions, where the sequence contains implicit relative time information. Intuitively, a predicted action sequence says “starting with the K-th step in the future, the policy outputs zeros actions for N steps, and starts moving at the (K+N)-th step”. So the behavior is Markovian again as long as the temporal confounder (pause) occurs within an action chunk.
Action smoothening
The second benefit discussed in ALOHA/ACT is action smoothening. Instead of executing the entire action chunk before predicting the next chunk, we could let the policy predict action chunks overlapped in time by increasing its control frequency. The advantage of this is that for any time step that gets an ensemble of actions, a weighted average of them will provide a smoother final action.

In the example above, the policy inference is performed every two steps but predicts three actions in a chunk. So every two steps we get two overlapped predicted actions ($a_3$). The two actions can be averaged to produce a potentially better action. In practice, we can further increase the overlapping window between two action chunks, and get a larger ensemble for every time step.
Outputting high-frequency actions
For some tasks that require high precision or dexterity, a high action frequency like 50HZ is necessary. However, it is impractical to expect a visuomotor policy to operate at such a high frequency, especially when there are multiple cameras. So the closed-loop method is definitely undesirable in this scenario, as it requires the network to generates an action within 20ms after receiving the inputs, so that the current inference won’t block the next one. With action chunking, we could let the policy operates at a much lower frequency like 1HZ, but asks it to output 50 actions in a chunk at a time. This is essentially what $\pi_0$ does [Physical Intelligence 2024]. In this way, we use a bigger and more powerful model to predict a future of 1s, with a much higher inference budget.
Handling model inference latency
The last benefit is also about model inference latency. So far our discussions of imitation learning have ignored the real deployment scenario which always creates a misalignment between the observation sequence and the action sequence. To see why this is the case, assume we have a closed-loop policy which is able to generate an action within 50ms and is operating at 10HZ.

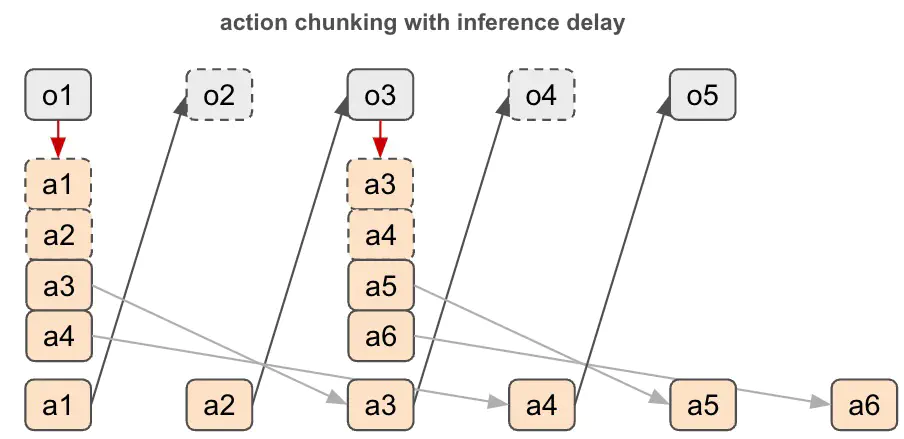
With the demonstration trajectory $(o_1,a_1), (o_2,a_2), \ldots$, our expectation is that the policy can correctly learn the mapping $o_t\rightarrow a_t$, so that when it does inference in real, ideally the same training trajectory will be reproduced. However, although 50ms is less than the control interval 100ms in this example, $a_1$ won’t be executed at the step of $o_1$, because it won’t be available until 50ms after. So the earliest step $a_1$ will be executed is after 100ms. In the figure we use a dashed box to denote an action available after its time step. Unfortunately, this has changed the environment dynamics and the policy behavior could be suboptimal.
Basically with closed-loop control, the policy is always generating actions for the past when we take inference latency into account. To compensate this, we can use action chunking to plan ahead by generating more actions into the future so that future time steps can use these lookahead actions for proper dynamics transition.

In the example above, the policy generates four actions $a_1,a_2,a_3,a_4$ at once, but due to inference latency, these actions won’t be available after $o_2$. To preserve the transition from $o_1$ to $o_3$, we could take $a_1,a_2$ from the previous chunk and execute them. Then $a_3,a_4$ in the current chunk will be used during the next policy inference at $o_3$. In this way, we can properly maintain the enviroment dynamics transition and guarantee the policy performance. Moreover, if there is an overlap between the effective action window (i.e., actions available before their time steps) of two chunks, we can again use smoothening to compute an averaged action.
Summary
In this article we have reviewed several benefits of action chunking for imitation learning. As a result, I believe it should be adopted by default for training a good policy from demonstration data. There are multiple ways to make the network output a sequence of actions at a time, for example, diffusion policy [Chi et al. 2023] and flow matching [Physical Intelligence 2024]. I expect to see more and more instances of action chunking policies for imitation learning in the coming year, in both academia and industry.